DigStat - Digitale Lerneinheiten in der Statistik
Section outline
-
-
Dieses Dokument enthält Informationen zur Verwendung der im Rahmen des Projekts DigStat veröffentlichten Materialien in Lehrveranstaltungen sowie zu ihrer Weiterentwicklung. Es richtet sich insbesondere an Dozierende, welche diese Materialien in ihrer Lehre einsetzen möchten.
-
-
Dieses Skript bietet Ihnen einen praxisnahen Einstieg in die Anwendung von R. Mithilfe theoretischer Erklärungen, praktischer Beispiele und Aufgaben lernen Sie, R für die Verarbeitung, Visualisierung und Interpretation von Daten einzusetzen.
-
In dieser Aufgabe nutzen Sie R, um die Häufigkeiten von Merkmalen in einer Datenmenge zu bestimmen. Dabei wenden Sie grundlegende statistische Auswertungsmethoden an.
-
In dieser Aufgabe nutzen Sie R, um die Quartile in der Verteilung eines Merkmals zu berechnen und den Interquartilsabstand zu bestimmen. Außerdem interpretieren Sie die Aussagekraft des Interquartilsabstands in Bezug auf die Streuung der Werte in einer Datenmenge.
-
In dieser Aufgabe verwenden Sie R, um zentrale statistische Kenngrößen wie den Mittelwert, die Standardabweichung und die Spannweite anhand eines Datensatzes zu berechnen.
-
-
Dieses Kapitel dient der Einführung in eine deskriptive statistische Analyse. Dazu werden zunächst die Schritte und Grundbegriffe einer statistischen Untersuchung eingeführt. Bei statistischen Analysen untersuchen wir sogenannte Merkmale. Diese werden auf verschiedenen Skalenniveaus gemessen, die hier vorgestellt werden.
-
In dieser Aufgabe sollen Sie noch einmal die Grundbegriffe einer statistischen Untersuchung rekapitulieren, indem Sie einen Lückentext ausfüllen.
-
In dieser Aufgabe ordnen Sie verschiedenen Merkmalen das zugeörige Skalenniveau zu.
-
In diesem Kapitel wird das Konzept der Häufigkeitsverteilung eines Merkmals mit gegebener Stichprobe beschrieben, die dazu dient Daten sinnvoll zusammenzufassen. Dazu werden absolute und relative Häufigkeiten von Merkmalsausprägungen eingeführt.
-
-
In diesem Kapitel werden eine Reihe von grafischen Methoden zur Darstellung von Häufigkeitsverteilungen beschrieben. Diese müssen je nach Merkmalstyp passend gewählt werden. Bei den grafischen Darstellungen handelt es sich um: Stab- und Balkendiagramm, Kreisdiagramm, Histogramm, Häufigkeitspolygon und die empirische Verteilungsfunktion. Weiter wird ein kurzer Überblick über die Kerndichteschätzung und den Boxplot gegeben.
-
In dieser Aufgabe klassieren Sie zunächst eine nominal skalierte Stichprobe und berechnen die absoluten und relativen Häufigkeiten der Klassen. Schließlich überlegen Sie noch welches Balkendiagramm zur den gegebenen Daten gehört.
-
In dieser Aufgabe klassieren Sie eine gegebene Stichprobe nach gegebenen Voraussetzungen und berechnen die relativen Häufigkeiten sowie die Häufigkeitsdichte (d.h. Balkenhöhe der Histogrammbalken) der einzelnen Klassen.
-
In dieser Aufgabe zeichnen Sie eine empirische Verteilungsfunktion für eine gegebene Stichprobe.
-
In dieser Aufgabe wird Ihnen eine empirische Verteilungsfunktion gezeigt und Sie müssen Fragen zu der zugrundeliegenden Stichprobe beantworten.
-
In diesem Kapitel wird das Konzept von Kennzahlen vorgestellt. Diese reduzieren die Informationen einer Stichprobe auf eine Zahl, welche dann eine gewisse Eigenschaft beschreibt. Wir beschäftigen uns besonders mit Kennzahlen der Lage und stellen dazu den Modalwert, das arithmetische Mittel, das geometrische Mittel, den Median und das \(p\)-Quantil vor. Außerdem wird der Boxplot eingeführt, welcher eine auf 5 Kennzahlen beruhende grafische Darstellung der Häufigkeitsverteilung ist.
-
In dieser Aufgabe liegen klassierte Daten vor und es muss ein arithmetisches Mittel berechnet werden. Dieses wird mit dem exakten arithmetischen Mittel der Ursprungsstichprobe verglichen.
-
In dieser Aufgabe werden verschiedene Lagemaße berechnet und entschieden in welchem Kontexten diese angewendet werden können.
-
In dieser Aufgabe wird das arithmetische Mittel und der Median berechnet und die Ergebnisse miteinander verglichen.
-
In dieser Aufgabe soll eine Wegstrecke optimiert werden. Dabei kann die Eigenschaft eines bestimmten Lagemaßes genutzt werden.
-
In dieser Aufgabe werden verschiedene Quantile für zwei Merkmale und Stichproben berechnet. Zusätzlich werden Sie Verständnisfragen zu Quantilen beantworten.
-
In dieser Aufgabe sehen Sie einen Boxplot und müssen dazu eine passende Stichprobe angeben.
-
In dieser Aufgabe sehen Sie einen Boxplot und müssen einige Fragen zu der zugrundeliegenden Stichprobe beantworten.
-
In dieser Aufgabe wird Ihnen eine Stichprobe gegeben und Sie müssen die Kennzahlen, die Sie zum Zeichnen eines verfeinerten Boxplots benötigen, angeben. Sie erhalten zum Schluss grafisches Feedback zu Ihrer Eingabe.
-
In diesem Kapitel wird das Thema Kennzahlen aus dem vorherigen Kapitel fortgesetzt. Kennzahlen reduzieren eine Stichprobe auf einen einzelnen Wert, der eine Eigenschaft der Häufigkeitsverteilung beschreibt. Wir konzentrieren uns nun auf Streuungsmaße und stellen dazu die Spannweite, den pp-Quantilsabstand, die empirische Varianz und Standardabweichung, die mediane absolute Distanz und die Entropie vor. Weiter besprechen wir die Schiefe und Wölbung von unimodalen Häufigkeitsverteilungen und geben jeweils eine Kennzahl dazu an.
-
In dieser Aufgabe werden Sie verschiedene Streuungsmaße berechnenen und zu diesen Verständnisfragen beantworten.
-
In dieser Aufgabe vergleichen wir die mittlere Jahrestemperaturen zweier Orte.
-
In dieser Aufgabe werden Sie anhand verschiedener Histogramme Fragen zur Schiefe und Wölbung beantworten.
-
Dieses Kapitel behandelt die zweidimensionale deskriptive Datenanalyse. Diese fokussiert sich auf die Untersuchung das Zusammenhangs zweier Merkmale. Dazu führen wir zunächst die zweidimensionale Häufigkeitsverteilung ein und erklären das Konzept von statistisch unabhängigen oder abhängigen Merkmalen. Um die Stärke eines statistischen Zusammenhangs zu quantifizieren kann man Zusammenhangsmaße verwenden. Hierzu besprechen wir verschiedene Kontingenzmaße und Korrelationsmaße. Letztere beschreiben insbesondere die Stärke eines linearen Zusammenhangs zweier mindestens ordinal skalierter Merkmale. Für einen linearen Zusammenhang können wir schließlich ein einfaches lineares Regressionsmodell bestimmen.
-
Diese Aufgabe beschäftigt sich mit der Abhängigkeit oder Unabhängigkeit von zweier in einer Stichprobe enthaltenen Merkmale.
-
Diese Aufgabe beschäftigt sich mit den bedingten Häufigkeiten einer zweidimensionalen Stichprobe.
-
In dieser Aufgabe werden Sie den Korrelationskoeffizient nach Pearson und den Korrelationskoeffizient nach Spearman berechnen sowie Verständnisfragen zu diesen beantworten.
-
In dieser Aufgabe werden die Koeffizienten \(\alpha\) und \(\beta\) einer Regressionsgerade Schritt-für-Schritt berechnet.
-
In dieser Aufgabe werden die Koeffizienten \(\alpha\) und \(\beta\) einer Regressionsgerade berechnet und eine Vorhersage für eine neue Beobachtung getroffen.
-
-
In diesem Kapitel behandeln wir den theoretischen Rahmen und das grundlegende Vorgehen der Schätztheorie. Wir übertragen Sachkontexte in statistische Modelle und definieren den Begriff des Schätzers.
-
In dieser Aufgabe lernen Sie, einen gegebenen Sachkontext durch ein statistisches Modell zu beschreiben. Der Sachkontext ist hier die Lebensdauer von Glühlampen.
-
In dieser Aufgabe lernen Sie, einen gegebenen Sachkontext durch ein statistisches Modell zu beschreiben. Der Sachkontext ist hier die Anzahl der in einer Stadt zugelassenen Taxis.
-
In dieser Aufgabe lernen Sie, einen gegebenen Sachkontext durch ein statistisches Modell zu beschreiben. Der Sachkontext ist hier die Messung der Stromstärke in einer elektrischen Schaltung.
-
In dieser Aufgabe lernen Sie, eine Schätzfunktion zu verwenden, um aus einer Stichprobe einen Schätzwert zu berechnen. Der Sachkontext ist hier die Lebensdauer von Glühlampen.
-
In dieser Aufgabe lernen Sie, eine Schätzfunktion zu verwenden, um aus einer Stichprobe einen Schätzwert zu berechnen. Der Sachkontext ist hier die Anzahl der in einer Stadt zugelassenen Taxis.
-
In diesem Kapitel behandeln wir mathematische Verfahren, mit denen Schätzer konstruiert werden können. Wir erklären jeweils das Prinzip, das dem Verfahren zugrunde liegt, und wenden es auf ausführlich durchgerechnete Beispiele an.
-
In dieser Aufgabe lernen Sie, einen Maximum-Likelihood-Schätzer zu berechnen. Die Zufallsvariablen folgen hier einer Gammaverteilung.
-
In dieser Aufgabe lernen Sie, einen Maximum-Likelihood-Schätzer zu berechnen. Die Zufallsvariablen folgen hier einer geometrischen Verteilung.
-
In dieser Aufgabe lernen Sie, einen Maximum-Likelihood-Schätzer zu berechnen. Die Zufallsvariablen folgen hier einer Gumbel-Verteilung.
-
In dieser Aufgabe lernen Sie, einen Maximum-Likelihood-Schätzer zu berechnen. Die Zufallsvariablen folgen hier einer Normalverteilung.
-
In dieser Aufgabe lernen Sie, einen Maximum-Likelihood-Schätzer zu berechnen. Die Zufallsvariablen folgen hier einer Pareto-Verteilung.
-
In dieser Aufgabe lernen Sie, einen Maximum-Likelihood-Schätzer zu berechnen. Die Zufallsvariablen folgen hier einer Poisson-Verteilung.
-
In dieser Aufgabe lernen Sie, einen Maximum-Likelihood-Schätzer zu berechnen. Die Zufallsvariablen folgen hier einer Weibull-Verteilung.
-
In dieser Aufgabe lernen Sie, den Momentenschätzer für den Parameter einer Exponentialverteilung zu berechnen.
-
In dieser Aufgabe lernen Sie, die Momentenschätzer für die beiden Parameter einer Gammaverteilung zu berechnen.
-
In dieser Aufgabe lernen Sie, den Momentenschätzer für den Parameter einer geometrischen Verteilung zu berechnen.
-
In dieser Aufgabe lernen Sie, die Momentenschätzer für die beiden Parameter einer kontinuierlichen Gleichverteilung zu berechnen.
-
In dieser Aufgabe lernen Sie, die Momentenschätzer für die beiden Parameter einer Lomax-Verteilung zu berechnen.
-
In diesem Kapitel behandeln wir mathematische Kriterien, mit denen die Qualität von Punktschätzern beurteilt werden kann. Wir untersuchen diese Eigenschaften eines Schätzers theoretisch und visualisieren sie mithilfe von Simulationen in R.
-
In dieser Aufgabe lernen Sie, einen Schätzer auf Erwartungstreue zu überprüfen und einen erwartungstreuen Schätzer zu konstruieren.
-
In dieser Aufgabe lernen Sie, gegebene Schätzer auf Erwartungstreue zu überprüfen und im Sinne der Effizienz zu vergleichen.
-
In dieser Aufgabe lernen Sie, gegebene Schätzer auf Erwartungstreue zu überprüfen und im Sinne der MSE-Effizienz zu vergleichen.
-
In dieser Aufgabe lernen Sie, den MSE von verschiedenen Schätzern im Bernoulli-Modell zu berechnen und die Schätzer auf MSE-Konsistenz zu überprüfen.
-
In dieser Aufgabe lernen Sie, in der mathematischen Modellierung einer Interview-Situation einen erwartungstreuen Schätzer zu konstruieren und diesen mit einem bereits bekannten Schätzer im Sinne der Effizienz zu vergleichen.
-
In diesem Kapitel behandeln wir die Berechnung von Konfidenzintervallen, mit denen Schätzunsicherheiten quantifiziert werden. Wir leiten für verschiedene Schätzprobleme Formeln zur Berechnung von Konfidenzintervallen her und visualisieren sie mithilfe von Simulationen in R.
-
In dieser Aufgabe lernen Sie, aus gegebenen Daten ein Konfidenzintervall für einen unbekannten Erwartungswert zu berechnen. Der Sachkontext ist hier die Qualitätskontrolle bei der Abfüllung von reinem Ethanol.
-
In dieser Aufgabe lernen Sie, aus gegebenen Daten ein Konfidenzintervall für einen unbekannten Erwartungswert zu berechnen. Der Sachkontext ist hier die Zubereitung einer isotonischen Kochsalzlösung.
-
In dieser Aufgabe lernen Sie, in einem Zweistichprobenproblem aus gegebenen Daten ein Konfidenzintervall für die Differenz der beiden unbekannten Erwartungswerte zu berechnen. Der Sachkontext ist hier die Qualitätskontrolle bei der Produktion von Tabletten eines bestimmten Arzneimittels.
-
In dieser Aufgabe lernen Sie, eine untere Schranke für den Stichprobenumfang zu berechnen, sodass ein Konfidenzintervall zu einer gegebenen Irrtumswahrscheinlichkeit eine vorher festgelegte Genauigkeit einhält. Der Sachkontext ist hier die Qualitätskontrolle bei der Abfüllung von reinem Ethanol.
-
In dieser Aufgabe lernen Sie, eine untere Schranke für den Stichprobenumfang zu berechnen, sodass ein Konfidenzintervall zu einer gegebenen Irrtumswahrscheinlichkeit eine vorher festgelegte Genauigkeit einhält. Der Sachkontext ist hier die Zubereitung einer isotonischen Kochsalzlösung.
-
In dieser Aufgabe lernen Sie, aus gegebenen Daten ein Konfidenzintervall für eine unbekannte Varianz zu berechnen. Der Sachkontext ist hier die Qualitätskontrolle bei der Abfüllung von reinem Ethanol.
-
In dieser Aufgabe lernen Sie, aus gegebenen Daten ein Konfidenzintervall für eine unbekannte Varianz zu berechnen. Der Sachkontext ist hier die Zubereitung einer isotonischen Kochsalzlösung.
-
-
Allgemeine Informationen zur Lerneinheit
Klicken Sie hier für mehr Informationen zu den Inhalten, Lernzielen und Voraussetzungen.
Inhalt
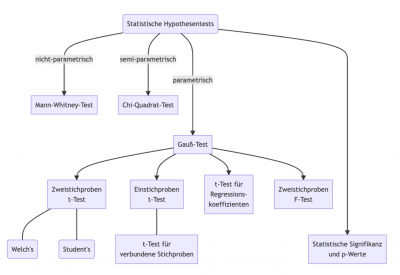
Die Lerneinheit Statistische Hypothesentests behandelt allgemeine Grundlagen der Test-Theorie. Außerdem werden Tests verschiedenen Typs eingeführt und deren Anwendung an Beispielen verdeutlicht. Sie besteht aus 9 Kapiteln:
- Inhaltliche Einführung und Grundbegriffe
- Gauß-Test als einführendes Beispiel für parametrische Tests
- Einstichproben-t-Test
- Zweistichproben-t-Test (unverbunden)
- t-Tests für verbundene Stichproben
- Hypothesentests in der linearen Regression und Simpson's Paradox
- F-Test
- Mann-Whitney-U-Test als Beispiel für einen nicht-parametrischen Test
- Chi-Quadrat-Unabhängigkeitstest als Beispiel für einen semi-parametrischen Test
Die folgende Abbildung zeigt die Bezüge zwischen den genannten Kapiteln. Knotenpunkte mit abgerundeten Ecken symbolisieren Unterthemen, die in dem hierarchisch höher angesiedelten Kapitel behandelt werden. Die Pfeile geben eine grobe Orientierung, in welcher Reihenfolge die Kapitel bearbeitet werden sollten. Verbindungen ohne Pfeil stellen Spezialfälle der darüberliegenden Tests dar.
Lernziele
Am Ende dieser Lerneinheit können Sie
- die grundlegenden Begriffe im Kontext statistischen Testens benennen.
- die Unterschiede zwischen parametrischen und nichtparametrischen Tests erläutern.
- zu einem vorliegenden Datensatz die passende Testart auswählen und einen entsprechenden Test anwenden.
Voraussetzungen
Grundkenntnisse in Wahrscheinlichkeitsrechnung werden vorausgesetzt. Beispielsweise sollten Binomial- und Normalverteilung bekannt sein.
Autor:innen
Diese Lerneinheit wurde von Riko Kelter, Alexander Schnurr und Susanne Spies unter Mithilfe von Annika Hirth an der Universität Siegen entwickelt.
-
Das einführende Video zur Lerneinheit Statistische Hypothesentests gibt einen Überblick über Aufbau und Inhalt der Materialien und mögliche Einsatzszenarien.
-
Das Video gibt eine Einführung in die Theorie statistischer Hypothesentests. Es erläutert grundlegende Konzepte und Objekte, die in der Theorie statistischen Testens nötig sind. Weiterführende Informationen finden sich auch im Kapitel zum Gauß-Test, das einen Einstieg in die Arbeit mit den restlichen Materialien bietet und viele der im Video angeschnittenen Konzepte aufgreift.
-
Wir behandeln in diesem Kapitel das Thema statistische Signifikanz von Hypothesentests und p-Werte. In der Auswertung von wissenschaftlichen Studien sind diese Begriffe von zentraler Bedeutung und sorgen nach wie vor oft für Missverständnisse. Ein solides Verständnis vom Konzept statistischer Signifikanz und p-Werten ist daher unerlässlich, um statistische Ergebnisse korrekt interpretieren zu können.
-
In dieser Aufgabe lernen Sie, wie Sie den p-Wert eines Hypothesentests interpretieren.
-
In dieser Aufgabe lernen Sie, wie Sie einen Binomialtest zur Überprüfung einer Hypothese verwenden. In Aufgabenteil (a) stellen Sie eine Hypothese auf. In Teil (b) führen Sie den Test durch. Dazu können sie R verwenden.
-
Wir behandeln in diesem Kapitel den Gauss-Test als einführendes Beispiel für einen parametrischen Hypothesentest. Die Herleitung der Teststatistik sowie praktische Beispiele veranschaulichen, wie der Test in R angewendet wird.
-
In dieser Aufgabe lernen Sie in fünf Teilaufgaben, wie Sie einen Zweistichproben-Gaußtest zur Überprüfung einer Hypothese verwenden.
-
In dieser Aufgabe lernen Sie in fünf Teilaufgaben, wie Sie einen Einstichproben-Gauß-Test zur Überprüfung einer Hypothese verwenden.
-
In dieser Aufgabe lernen Sie, wie Sie mithilfe eines Gauß-Tests den Mittelwert einer Stichprobe überprüfen.
-
In dieser Aufgabe lernen Sie, wie Sie mithilfe eines Gauß-Tests den Mittelwert zweier Stichproben vergleichen.
-
-
Wir behandeln in diesem Kapitel den Einstichproben-t-Test. Der Hypothesentest ist unter den am häufigsten in der Praxis eingesetzten parametrischen Tests. Der Einstichproben-t-Test verallgemeinert den Gauß-Test für eine Stichprobe und setzt die Varianz ebenfalls als unbekannt voraus. Ein praktisches Beispiel veranschaulicht, wie der t-Test in R angewendet wird.
-
In dieser Aufgabe lernen Sie in fünf Teilaufgaben, wie Sie einen zweiseitigen Einstichproben-t-Test zur Überprüfung einer Hypothese verwenden.
-
In dieser Aufgabe lernen Sie, wie Sie ein Konfidenzintervall berechnen. In Aufgabenteil (a) bestimmen Sie den dazugehörigen Standardfehler. In Teil (b) bestimmen Sie die Intervallgrenzen.
-
In dieser Aufgabe lernen Sie in fünf Teilaufgaben, wie Sie einen einseitigen Einstichproben-t-Test zur Überprüfung einer Hypothese verwenden und auswerten.
-
Wir behandeln in diesem Kapitel den t-Test für zwei unverbundene Stichproben. Dieser ist einer der am häufigsten in der Praxis eingesetzten parametrischen Hypothesentests. Die Unterschiede zwischen Student’s und Welch’s t-Test werden diskutiert und die Teststatistik motiviert und erläutert. Praktische Beispiele veranschaulichen, wie der Test in R angewendet wird.
-
In dieser Aufgabe lernen Sie in fünf Teilaufgaben, wie Sie einen Zweistichproben-t-Test zur Überprüfung einer Hypothese verwenden.
-
Wir behandeln in diesem Kapitel den t-Test für zwei verbundene Stichproben. Der Hypothesentest ist unter den am häufigsten in der Praxis eingesetzten parametrischen Tests. Der t-Test für zwei verbundene Stichproben wird beispielsweise angewandt, wenn zwei Messungen derselben Individuen beziehungsweise Beobachtungseinheiten zu unterschiedlichen Zeitpunkten gemacht wurden und diese Messungen damit nicht mehr unabhängig voneinander sind. Es wird gezeigt, dass der t-Test für zwei verbundene Stichproben sich auf den Einstichproben-t-Test zurückführen lässt, die Teststatistik wird motiviert und erläutert. Ein praktisches Beispiel veranschaulicht, wie der t-Test für zwei verbundene Stichproben in R angewendet wird.
-
In dieser Aufgabe lernen Sie, wie Sie einen zweiseitigen Zweistichproben-t-Test zur Überprüfung einer Hypothese verwenden.
-
Wir behandeln in diesem Kapitel den t-Test für Regressionskoeffizienten im linearen Regressionsmodell.
-
In dieser Aufgabe lernen Sie in fünf Teilaufgaben, wie Sie einen t-Test für Regressionskoeffizienten zur Überprüfung einer Hypothese verwenden.
-
In dieser Aufgabe lernen Sie in zwei Teilaufgaben, wie Sie einen t-Test für Regressionskoeffizienten zur Überprüfung einer Hypothese verwenden.
-
Wir behandeln in diesem Kapitel den F-Test für zwei Stichproben. Dieser eignet sich dazu, zwei Stichproben aus unterschiedlichen, normalverteilten Populationen auf Unterschiede in den Varianzen zu prüfen.
-
In dieser Aufgabe lernen Sie, wie Sie einen einseitigen F-Test zur Überprüfung einer Hypothese zur Varianz zweier Stichproben anwenden.
-
Wir behandeln in diesem Kapitel den Mann-Whitney-U-Test für zwei unverbundene Stichproben, welcher eine nichtparametrische Alternative zum t-Test für zwei unverbundene Stichproben darstellt. Wir erläutern die Idee hinter dem Test, zeigen die Durchführung in R anhand eines Anwendungsbeispiels und diskutieren Vor- und Nachteile sowie die Voraussetzungen des Tests.
-
In dieser Aufgabe lernen Sie, wie Sie einen U-Test zur Überprüfung einer Hypothese zur Verteilung zweier Merkmale verwenden.
-
Wir behandeln in diesem Kapitel den Chi-Quadrat-Unabhängigkeitstest und dessen Anwendung in Kontingenztafeln.
-
In dieser Aufgabe lernen Sie in drei Teilaufgaben, wie Sie einen Chi-Quadrat-Unabhängigkeitstest zur Überprüfung einer Hypothese verwenden.
-
In dieser Aufgabe lernen Sie in fünf Teilaufgaben, wie Sie einen Chi-Quadrat-Unabhängigkeitstest zur Überprüfung einer Hypothese verwenden.
-
-
-
In diesem Kapitel behandeln wir die einfache lineare Regression. Wir erklären das zugrunde liegende statistische Modell und wie mithilfe der Kleinste-Quadrate-Methode Schätzwerte für die Parameter der Regressionsgeraden ermittelt werden können.
-
In dieser Aufgabe lernen Sie, wie Sie eine Regressionsgerade bestimmen, indem Sie die Steigung und den \(y\)-Achsenabschnitt aus zusammengefassten Daten schätzen. Weiter lernen Sie, wie man Konfidenzintervalle für die Parameter bestimmt.
-
In dieser Aufgabe lernen Sie, wie Sie eine lineare Regression mithilfe von R ausführen. Zur Bearbeitung der Aufgabe ist R nicht notwendig.
-
In diesem Kapitel behandeln wir einen Hypothesentest und Konfidenzintervalle für die einfache lineare Regression. Wir erklären, wie Konfidenzintervalle berechnet werden und wie die Hypothese getestet werden kann, dass die Regressionsgerade eine vorgegebene Steigung \(\beta_0\) aufweist. Insbesondere werden wir erklären, wie die Hypothese getestet werden kann, dass die erklärende Variable keinen Einfluss auf die abhängige Variable hat.
-
In dieser Aufgabe lernen Sie, wie Sie in einem einfachen linearen Modell einen Hypothesentest zum Einfluss der unabhängigen Variable auf die abhängige Variable durchführen.
-
In dieser Aufgabe lernen Sie, wie Sie die lineare Abhängigkeit zwischen zwei Variablen mithilfe einer R-Ausgabe bestimmen.
-
In diesem Kapitel stellen wir das multiple lineare Regressionsmodell vor, das zur Modellierung von Experimenten dient, bei denen das Ergebnis von mehreren erklärenden Variablen abhängt. Zur Schätzung der Parameter werden wir die Kleinste-Quadrate-Methode vorstellen, die Eigenschaften des Schätzers analysieren und Konfidenzintervalle bestimmen. Weiter werden wir zeigen, wie man Daten mithilfe des multiplen linearen Regressionsmodells in R analysieren kann.
-
In dieser Aufgabe lernen Sie, wie man die Designmatrix eines linearen Regressionsmodells angibt, wie man den Kleinste-Quadrate-Schätzer bestimmt und wie man einen künftigen Wert der abhängigen Variablen zu vorgegebenen Werten der erklärenden Variablen vorhersagen kann.
-
In diesem Kapitel stellen wir zunächst zum multiplen linearen Regressionsmodell das Bestimmtheitsmaß \(R^2\) vor, das auch unter dem Namen multipler Korrelationskoeffizient bekannt ist. Das Bestimmtheitsmaß gibt an, welcher Anteil der Streuung in den Ergebnissen der Experimente durch das Modell erklärt wird. Weiter werden wir den F-Test vorstellen, mit dessen Hilfe wir Hypothesen über die Parameter im multiplen linearen Regressionsmodell testen können. Schließlich werden wir erklären, wie man die vorgestellten Verfahren in R bei gegebenen Daten ausführen kann.
-
In dieser Aufgabe lernen Sie, wie Sie in einem linearen Regressionsmodell zu einem gegebenen Datensatz das Bestimmtheitsmaß mithilfe von R berechnen und wie Sie einen F-Test für die Hypothese, dass einige der erklärenden Variablen keinen Einfluss auf die abhängige Variable haben, durchführen.